一、他们是谁
他们是爱卡丝俱乐部,一家成立于2021年1月28日的新兴团体。三位俱乐部成员分别是苏天祺、程昕、薛睿鑫,均是南京大学电子系二年级研究生,俱乐部名称取自南京大学ICAIS实验室的音译。俱乐部的指导老师是IEEE Fellow 王中风教授。

成员合影(左起)程昕 苏天祺 薛睿鑫
二、他们做了什么
他们俱乐部参加了第五届集成电路创新创业大赛(海云捷迅杯),针对MobileNet V1的硬件加速器进行优化。一路过关斩将,熬夜调通代码,更新迭代结果在华东分赛区获得二等奖。最后绞尽脑汁进行优化,终于在全国总决赛获得海云捷迅杯一等奖(企业大奖)。

俱乐部成员程昕为他们的优化方案起名叫“基于稀疏卷积与层融合的流水线优化方案”。优化手段分别放在量化、排序、传输、计算、流水线这五个方面。通过优化,他们将原3000ms的预测时间,压缩到接近800ms,速度提升超过3.5倍。

(整体的优化思路和手段)
最后的推理效果和时间效果如图(若将第二层卷积放在arm上进行,速度会慢一点但是精度会高一些)

所有卷积在FPGA上进行,速度快,精度稍低(左图);第二层卷积在ARM上进行,速度稍慢,但是精度高(右图)
三、他们的作品
他们的任务是需要针对基于MobileNet V1的SSD目标检测算法加速器进行优化,以达到快速的目标检测效果。

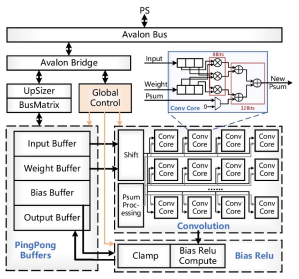
1.整体架构
Data (数据)经UpSizer和BusMatrix进行仲裁,存储到相应的SRAM中,他们将PingPong Buffer取代原SRAM,用来实现数据传输和计算的并行;重新设计卷积模块,并将卷积结果直接传入BiasRelu单元,二者采用层融合的方式连接,以便提高数据读写和传输效率。
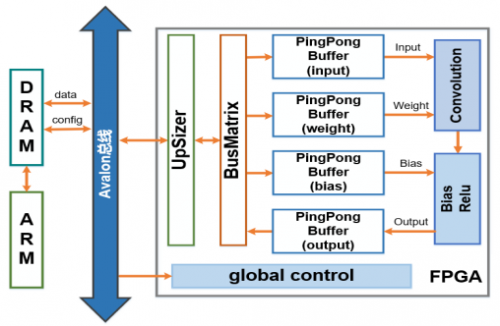
(整体的架构图)
2.卷积重构
他们采用row-wise,weight stationary的方式重新设计卷积模块,并将乘法的并行度提高到96(3x32)使得网络可以同时计算32个卷积核的一行数据,以加快卷积的计算速度并提高片上数据的复用性。
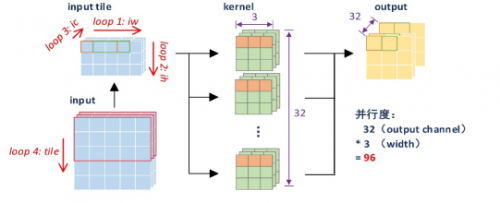
(普通卷积的计算数据流)
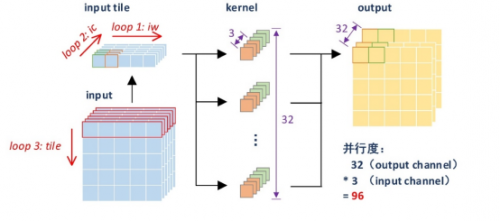
(逐点卷积的计算数据流)
3.流水线优化
为了进一步提高计算流水,他们将卷积(Conv)和偏移、激活(BiasReLU)融合起来并加入PingPong Buffer。
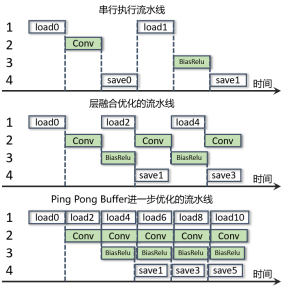
4.量化方案
他们也对量化过程进行优化,并在推理前对完成对数据的量化并保存结果。以减少权重的重复量化。
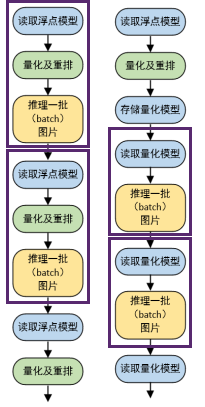
(量化过程示意图)
5.硬件架构
上述架构的硬件设计如图所示。他们设计的硬件单元包括包含32个Conv Core;每个Conv Core包括3个8bits乘法器和3个32bits加法器;Psum Processing负责累加并存储卷积计算的中间值。
6.优化结果
经过他们的优化,在不同卷积层的加速达到了最高39倍加速比,平均4.5倍加速比。并且将整体的目标识别速度提升到了最快836ms!
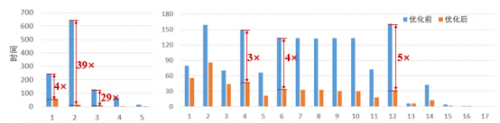
普通卷积层(左)和逐点卷积层加速比
四、海云捷迅对他们的评价
对于爱卡丝俱乐部,重庆海云捷迅科技有限公司资深架构师万毅做出如下评价:
南京大学的获奖团队,首先对模型demo耗时的地方做了详细的定量分析,准确的找出了影响性能的问题所在,并根据分析结果,系统的提出和实现了改进措施。在量化策略、数据搬运、卷积实现、剪枝、并行化方面都做了有效的工作,同时文档、汇报ppt、代码注释也做的完善和仔细,测试效果经过评测达到了较好的效果,参赛的团队做了很多行之有效的工作,是一个优秀的团队。
——重庆海云捷迅科技有限公司资深架构师 万毅
五、他们的获奖心得
爱卡丝俱乐部整个暑假都埋头苦干,终于一路披荆斩棘,最后拿到了想要的名次。让我们来听听各个成员的参赛心得吧!
苏天祺:在这次比赛中,每位成员都有着很强的责任感和任务意识,大家主动给自己分配了需要学习的内容,所以即使是初次接触,我们的准备也足够。而且凡是遇到困难,我们都会相互讨论并且请教有经验的学长和老师,比赛气氛简直不要太好!
程昕:我们每周都会开会啊,大家一股脑把问题抛出来然后相互讨论,我们就会碰撞出很多的火花。我们也会给自己规定时间轴(虽然经常做不完),但是给自己一个ddl,自己就有很多的动力!
薛睿鑫:其实我们初赛过后,性能并不是很好,但是大家也都不气馁,也没放弃,那个STP一直连不上,简直要崩溃了,但是一遍一遍的尝试,一遍一遍的请教相关老师,终于出了结果,我们都非常高兴。
 【大爱之行 】华宇集团董事长赵
【大爱之行 】华宇集团董事长赵 百淘传媒是一家专注于抖音直播运
百淘传媒是一家专注于抖音直播运 《非正式会谈》6.5季收官 打造世
《非正式会谈》6.5季收官 打造世 数字化时代,获得场景视频助力企
数字化时代,获得场景视频助力企


